


Updated on May 29, 2026
Accessing printed text in a mobile context is a major challenge for the blind. A preliminary study with blind people reveals numerous difficulties with existing state-of-the-art technologies including problems with alignment, focus, accuracy, mobility and efficiency. In this paper, we present a finger-worn device, FingerReader, that assists blind users with reading printed text on the go.
We introduce a novel computer vision algorithm for local-sequential text scanning that enables reading single lines, blocks of text or skimming the text with complementary, multimodal feedback. This system is implemented in a small finger-worn form factor, that enables a more manageable eyes-free operation with trivial setup. We offer findings from three studies performed to determine the usability of the FingerReader.
Researchers in both academia and industry exhibited a keen interest in aiding people with VI to read printed text. The earliest evidence we found for a specialized assistive text-reading device for the blind is the Optophone, dating back to 1914 [3]. However the Optacon [10], a steerable miniature camera that controls a tactile display, is a more widely known device from the mid 20th century. Table 1 presents more contemporary methods of text-reading for the VI based on key features: adaptation for non-perfect imaging, type of text, User Interface (UI) suitable for VI and the evaluation method. Thereafter we discuss related work in three categories: wearable devices, handheld devices and readily available products. As our device is finger worn, we refer the reader to our prior work that presents much of the related finger worn devices [12], and to [16] for a limited survey of finger-worn devices for general public use. Additionally, we refer readers to the encompassing survey by Lev´esque [9] for insight into the use of tactiles in assistive technology.
In a wearable form-factor, it is possible to use the body as a directing and focusing mechanism, relying on proprioception or the sense of touch, which are of utmost importance for people with VI. Yi and Tian placed a camera on shade-glasses to recognize and synthesize text written on objects in front of them, and Hanif and Prevost’s did the same while adding a handheld device for tactile cues. Mattar et al. are using a head-worn camera, while Ezaki et al. developed a shoulder-mountable camera paired with a PDA . Differing from these systems, we proposed using the finger as a guide , and supporting sequential acquisition of text rather than reading text blocks . This concept has inspired other researchers in the community
Mobile phone devices are very prolific in the community of blind users for their availability, connectivity and assistive operation modes, therefore many applications were built on top of them: the kNFB kReader1, Blindsight’s Text Detective2, ABBYY’s Text Grabber3, StandScan4, SayText5, ZoomReader6 and Prizmo7. Meijer’s vOICe for Android project is an algorithm that translates a scene to sound; recently they introduced OCR capabilities and enabling usage of Google Glass8. ABiSee’s EyePal ROL is a portable reading device, albeit quite large and heavy9, to which OrCam’s recent assistive eyeglasses10 or the Intel Reader11 present a more lightweight alternative.
Prototypes and products in all three categories, save for [23], follow the assumption that the goal is to consume an entire block of text at once, therefore requiring to image the text from a distance or use a special stand. In contrast, we focused on creating a smaller and less conspicuous device, allowing for intimate operation with the finger that will not seem strange to an outside onlooker, following the conclusions of Shinohara and Wobbrock [21]. Giving the option to read locally, skim over the text at will in a varying pace, while still being able to read it through, we sought to create a more liberating reading experience.
FingerReader is an index-finger wearable device that supports the blind in reading printed text by scanning with the finger and hearing the words as synthesized speech (see Figure 1c). Our work features hardware and software that includes video processing algorithms and multiple output modalities, including tactile and auditory channels. The design of the FingerReader is a continuation of our work on finger wearable devices for seamless interaction [12, 19], and inspired by the focus group sessions. Exploring the design concepts with blind users revealed the need to have a small, portable device that supports free movement, requires minimal setup and utilizes real-time, distinctive multimodal response. The finger-worn design keeps the camera in a fixed distance from the text and utilizes the inherent finger’s sense of touch when scanning text on the surface. Additionally, the device provides a simple interface for users as it has no buttons, and affords to easily identify the side with the camera lens for proper orientation.

The FingerReader hardware features tactile feedback via vibration motors, a dual-material case design inspired by the focus group sessions and a high-resolution mini video camera. Vibration motors are embedded in the ring to provide tactile feedback on which direction the user should move the camera via distinctive signals. Initially, two ring designs were explored: 4 motor and 2 motor (see Fig. 1a). Early tests with blind users showed that in the 2 motor design signals were far easier to distinguish than with the 4 motor design, as the 4 motors were too close together. This led to a new, multi-material design using a white resin-based material to make rubbery material for the flexible connections. The dual material design provides flexibility to the ring’s fit as well as helps dampen the vibrations and reduce confusion for the user.
We developed a software stack that includes a sequential text reading algorithm, hardware control driver, integration layer with Tesseract OCR [22] and Flite Text-to-Speech (TTS) [2], currently in a standalone PC application (see Fig. 2).
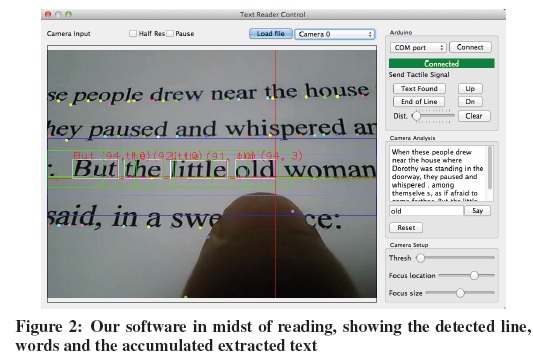
The sequential text reading algorithm is comprised of a number of sub-algorithms concatenated in a state-machine (see Fig. 3), to accommodate for a continuous operation by a blind person. The first two states (Detect Scene and Learn Finger) are used for calibration for the higher level text extraction and tracking work states (No Line, Line Found and End of Line). Each state delivers timely audio cues to the users to inform them of the process. All states and their underlying algorithms are detailed in the following sections. The operation begins with detecting if the camera indeed is looking at a close-up view of a finger touching a contrasting paper, which is what the system expects in a typical operation.
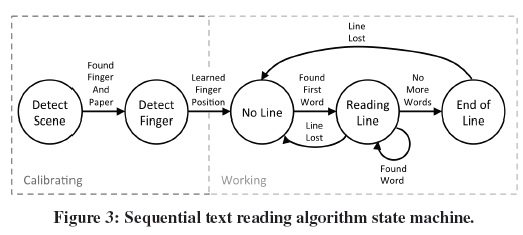
Once achieving a stable view, the system looks to locate the fingertip as a cursor for finding characters, words and lines. The next three states deal with finding and maintaining the working line and reading words. For finding a line, the first line or otherwise, a user may scan the page (in No Line mode) until receiving an audio cue that text has been found. While a text line is maintained, the system will stay in the Line Found state, until the user advanced to the end of the line or the line is lost (by moving too far up or down from the line or away from the paper).
The initial calibration step tries to ascertain whether the camera sees a finger on a contrasting paper. The input camera image is converted to the normalized-RGB space: (R, G, (B)= rg),, b, however we keep only r+g+br+g+br+g+b thenormal-ized red channel (R) that corresponds well with skin colors and ameliorates lighting effects. The monochromatic image is downscaled to 50x50 pixels and matched to a dataset of prerecorded typical images of fingers and papers from a proper perspective of the device camera. To score an incoming example image, we perform a nearest neighbor matching and use the distance to the closest database neighbor. Once a stable low score is achieved (by means of a running-window of 20 samples and testing if μscore +2o< t hreshold) the system deems the scene to be a well-placed finger on a paper, issues an audio command and advances the state machine.
In the finger detection state we binarize the R channel image using Otsu adaptive thresholding and line scan for the top white pixel, which is considered a candidate fingertip point (see Fig. 4). During this process the user is instructed not to move, and our system collects samples of the fingertip location from which we extract a normal distribution. In the next working states the fingertip is tracked in the same fashion from the R channel image, however, in this case, we assign each detection with a probability measure based on the learned distribution to erradicate outliers. The inlying fingertip detection guides a local horizontal focus region, located above the fingertip, within which the following states perform their operations. The focus region helps with efficiency in calculation and also reduces confusion for the line extraction algorithm with neighboring lines (see Fig. 5). The height of the focus region may be adjusted as a parameter, but the system automatically determines it once a text line is found.
Within the focus region, we start with local adaptive image binarization (using a shifting window and the mean intensity value) and selective contour extraction based on contour area, with thresholds for typical character size to remove outliers. We pick the bottom point of each contour as the baseline point, allowing some letters, such as ‘y’,’g’ or ‘j’ whose bottom point is below the baseline, to create artifacts that will later be pruned out. Thereafter we look for candidate lines by fitting line equations to triplets of baseline points; we then keep lines with feasible slopes and discard those that do not make sense. We further prune by looking for supporting baseline points to the candidate lines based on distance from the line. Then we eliminate duplicate candidates using a 2D histogram of slope and intercept that converges similars lines together. Lastly, we recount the corroborating baseline points, refine the line equations based on their supporting points and pick the highest scoring line as the detected text line. When ranking the resulting lines, additionally, we consider their distance from the center of the focus region to help cope with small line spacing, when more than one line is in the focus region.
We contributed FingerReader, a novel concept for text reading for the blind, utilizing a local-sequential scan that enables continuous feedback and non-linear text skimming. Motivated by focus group sessions with blind participants, our method proposes a solution to a limitation of most existing technologies: reading blocks of text at a time. Our system includes a text tracking algorithm that extracts words from a close-up camera view, integrated with a finger-wearable device. A technical accuracy analysis showed that the local-sequential scan algorithm works reliably. Two qualitative studies with blind participants revealed important insights for the emerging field of finger-worn reading aids. First, our observations suggest that a local-sequential approach is beneficial for document exploration–but not as much for longer reading sessions, due to troublesome navigation in complex layouts and fatigue.
Access to small bits of text, as found on business cards, pamphlets and even newspaper articles, was considered viable. Second, we observed a rich set of interaction strategies that shed light onto potential real-world usage of finger-worn reading aids. A particularly important insight is the direct correlation between the finger movement and the output of the synthesized speech: navigating within the text is closely coupled to navigating in the produced audio stream.
Our findings suggest that a direct mapping could greatly improve interaction (e.g. easy “re-reading”), as well as scaffold the mental model of a text document effectively, avoiding “ghost text”. Last, although our focus sessions on the feedback modalities concluded with an agreement for cross-modality, the thorough observation in the follow-up study showed that user preferences were highly diverse. Thus, we hypothesize that a universal finger-worn reading device that works uniformly across all users may not exist (sensu [20]) and that personalized feedback mechanisms are key to address needs of different blind users.
1. Bigham, J. P., Jayant, C., Ji, H., Little, G., Miller, A.,Miller, R. C., Miller, R., Tatarowicz, A., White, B., White, S., and Yeh, T. Vizwiz: Nearly real-time answersto visual questions. In Proc. of UIST, ACM (2010), 333–342.
2. Black, A. W., and Lenzo, K. A. Flite: a small fast run-time synthesis engine. In 4th ISCA Tutorial and Research Workshop (ITRW) on Speech Synthesis (2001).
3. d’Albe, E. F. On a type-reading optophone. Proceedings of the Royal Society of London. Series A 90, 619 (1914), 373–375.
4. Ezaki, N., Bulacu, M., and Schomaker, L. Text detection from natural scene images: towards a system forvisually impaired persons. In Proc. of ICPR, vol. 2 (2004), 683–686.
5. Hanif, S. M., and Prevost, L. Texture based text detection in natural scene images-a help to blind and visually impaired persons. In CVHI (2007).
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
