


Published on Nov 30, 2023
In this report, SmartSur system is discussed, which is a smart video surveillance system that is capable of detecting a pair-wise event called peope-meet. SmartSur mainly consist of three stages: pre-processing, human detection and event detection. The pre-processing can be decomposed into four major stages: background subtraction, noise elimination and hole filling, contour recognition and object labelling. All these four stages together help to find the moving foreground objects from the raw input video frame. Human detection focuses on finding human from the detected foreground objects which involves 3 major stages, namely HOG feature extraction, SVM training and SVM testing. In the event detection part of the system, a manually defined event called people-meet will be detected based on the position of the detected human. The system is developed on C++ platform using OpenCV as the core library. Besides, the implemented system is tested by the AVSS surveillance video database with a well-recognized result.
1. Read and study the related computer vision techniques from the existing surveillance video analysis projects and design the framework for SmartSur
2. Study and compare among many of the different background subtraction algorithms and choose one to use in SmartSur
3. Study HOG algorithm and SVM on pedestrian detection
4. Implement the system in C++ with OpenCV as the core library
Surveillance systems are of critical importance to public safety and security. Video cameras have been widely installed in surveillance system and currently more than 8,500,000 cameras were installed in China for surveillance in the year 2010. This results in a huge amount of surveillance videos that need to be analysed. If this task is to be done by human resource, then it could be extremely inefficient while nothing can be ensured for its accuracy. Besides, the lack of ability for human to monitor several different videos simultaneously is another drawback if human resources are used for real-time monitoring of surveillance videos. Motivated by this exigent requirement in real application, efficient and effective strategies for event detection, especially human behaviour detection, in surveillance video is becoming a popular research area.
It is proposed to develop a new surveillance system which is built on HOG as the core algorithm to take charge of the job for surveillance video analysis. The event I focus to detect is a pair-wise event from the TRECVid SED task in 2009 called people-meet. In order to do that, the previous stages of pre-processing of the video frame and human detection of the detected foreground objects have to be done in advance. Here I manually define the people-meet event as an event that the Euclidean distance of two human objects can pass a threshold filter of the frame. The reason why we did not use a machine learning module to classify the event is the lack of training data for this event and also the simplicity of the implementation.
The framework of SmarSur is illustrated in Figure 2.1.1. The first stage of the system is called pre-processing which mainly focuses some of the image processing and conversion operations as the advanced work for the system. In more detail, it can be further decomposed into four parts, namely background subtraction, noise elimination & hole filling, contour recognition and finally the object labelling. More details about this stage will be included in section 3. After the first stage of pre-processing, the moving foreground objects will be detected and labelled from the video frame. But an important issue about this is that nothing has been done to determine whether or not what we have in the foreground objects are human as the ultimate task in this system is to find a human-related event called people-meet. So in stage three we will have human detection done to do that job.
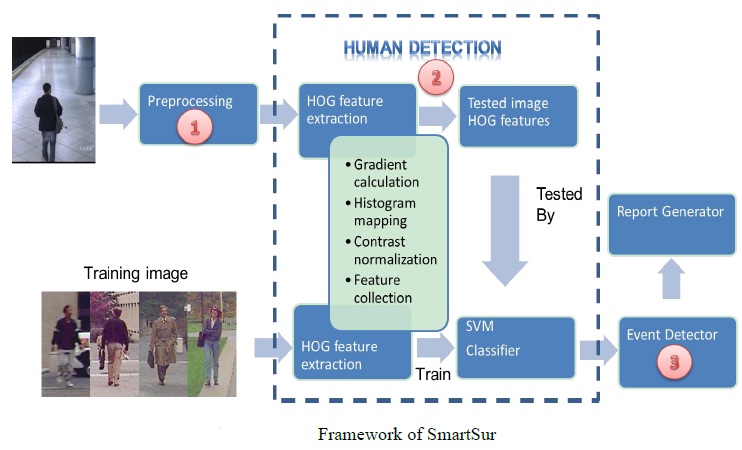
Human detection follows the concept of machine learning which have two phases, namely the training phase and the testing phase. The algorithm called HOG (Histogram of Oriented Gradients) will be adopted as the feature extraction algorithm in this part. HOG is a well-known algorithm that is specially designed for the detection of human pedestrian. The last stage is event detection. The event we are going to detect is called peoplemeet. It is one of the events from the TRECVid SED 2009 tasks. I chose this event as the target-event for SmartSur is because its simplicity. The event can be detected in each individual video frame. So no object tracking and event classification is needed
OpenCV (Open Source Computer Vision Library) is a library of programming functions mainly aimed at real time computer vision. It is developed by Intel and now have cross-platform support. OpenCV is so powerful that it provides all the core functions that enable the system to do matrix operation, image filtering, colour transformation and so on.
The topic of human detection is one of the most challenging tasks in the field of computer vision owing to their variable appearance and wide range of poses that they can adopt. Apart from that, there are some other factors that make human detection a very tough challenge. The challenges are classified as:
1. Wide variety of articulated poses
2. Variable appearance/ clothing
3. Complex backgrounds
4. Unconstrained illumination
5. Occlusions
6. Different Scales
Even though this is a tough task, many projects conducted have successfully overcome these challenges and obtained a good result of human detection. They are done from different approaches but if we do the classification, we can have a clear review about these projects and their related techniques.
The detection technique is based on the novel idea of the wavelet template that defines the shape of an object in terms of a subset of the wavelet coefficients of the image. It is invariant to changes in color and texture and can be used to robustly define a rich and complex class which is very suitable for detection of people.
This detection technique uses very simple features called rectangular differential features to be classified by the weak classifiers. Then these weak classifiers are sent into the adaBoost. AdaBoost has the functionality that by combining many weak classifiers together and iterate to update each weak classifier ’s weight, finally result in a strong classifier. As the time for calculating the rectangular differential features and doing weak classification is small. This kind approach comes with a good real time effect.
Mikolajczyk et al use combinations of orientation position histograms with binarythresholded gradient magnitudes to build a parts based method containing detectors for faces, heads, and front and side profiles of upper and lower body parts.
This paper presents an efficient shape-based object detection method using Distance Transforms(DTs). A DT converts the binary image, which consists of feature and non-feature pixels, into a DT image where each pixel denotes the distance to the nearest feature pixel.
W.T. Freeman did a good job on detection of hand gesture for game industry by using orientation histogram which is a great base for the development of HOG. Besides the Scale Invariant Feature Transformation (SIFT) is very similar to the technique of HOG. It approach to wide baseline image matching, in which it provide the underlying image patch descriptor for matching scale invariant keypoints.
It uses binary edge-presence voting into log-polar space bines, irrespective of edge orientation.
The descriptors used in PCA-SIFT are based on projecting gradient image onto a basis learned from training images using PCA. After having a review of roughly the history of human detection technique, let us come to the standard technique.
In vector calculus, the gradient of a scalar field is a vector field that points in the direction of the greatest rate of increase of the scalar field. And the magnitude is just the rate of the increase. It is very straight-forward to illustrate this concept with the help of Figure
If black here in these two images represent a higher value, then the gradient of a given point is just the vector that shows the direction of change of the scalar from low to high. One thing that is worthy of noticing is that each pixel in an image can have gradient. As the gradient is the vector that represents the rate and direction of its scalar change, intensity change in this example, we can do the calculation of gradient easily by do the onedimensional derivative function for both x and y direction of the point and treat them as the x and y value of the vector. The detailed implementation process will be illustrated later. After knowing the basic concepts that forms the basis of this technique, let us have a view about what ideas lead to this technique.

The gradient is actually a good feature that helps to find the edge of the figure in an image. The resulted outline is not concerned with the texture change. Thus if we record the gradient information in an orientation histogram, all the information we need about this image can be saved. By doing contrast normalization of these histograms, the change of illumination can also be eliminated. Apart from that , from the observation some of the small pose change can also be eliminated by using this method. Then the histograms are used as the feature vectors for the classifier which is just SVM in this case
A SVM (support vector machine) is a concept in statistics and computer science for supervised learning method that analyse data and recognize patterns, used for classification and regression analysis. The standard SVM takes a set of input data and predicts, for each given input, which of two possible classes forms the input, making the SVM a nonprobabilistic binary linear classifier. Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples into one category or the other. An SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall on. SVM is just one of the algorithms available that can be used as classifiers. The definition of classifier can be clearly illustrated by Figure
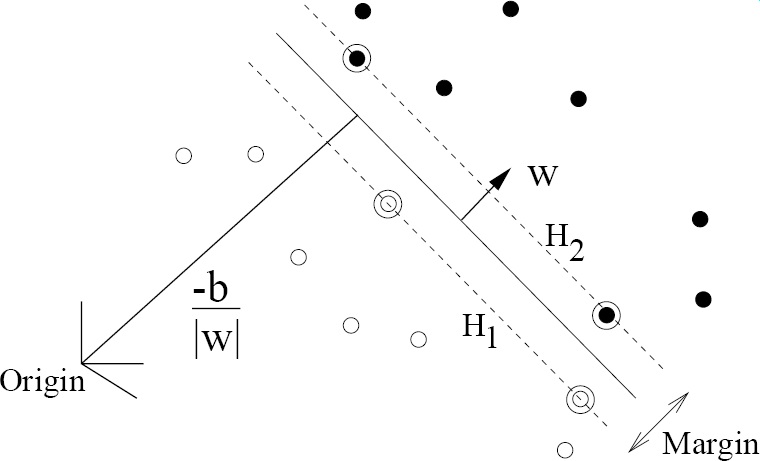
In a two-dimensional world, we build up a coordinate as normal. In the coordinate there are many of the points. Some of the points are positive while some are negative. The classifier is just a line that separates these two groups of points well. And SVM is one of the algorithms that determine how to find such a line. A set of training data containing both positive and negative samples have to be used to train SVM to find such a line. Once SVM is trained which means the separating line is found, the test data can be sent into SVM to be tested to determine whether or not it is positive or negative. Of course in real application, the data can never in two-dimension. It may be in multi-dimensional space so the separator will be a hyperplane . SVM is actually the very famous algorithm for machine learning for its high accuracy, fast operation and variant input dimension support.
The training data that we use are from two pedestrian dataset, namely the MIT pedestrian database and INRIA pedestrian database. MIT pedestrian database contains 509 training samples. And INRIA pedestrian database contains 1805 images.
The event detection is our final target. The event we are aimed to detect is called peoplemeet. There are two approaches to deal with the event detection module of the system. 1. Manually define the event and deal with detection in the implementation 2. Use supervised learning to handle the event detection. The first one is preferable if the event we are going to detect is relatively easy to define like people-run. We may call it people run if the tracked person moves in a speed that reaches a certain threshold. But sometimes it can be difficult to define. The people-meet event here is just an event that you cannot define easily in the language of computer. The second approach is relatively a common solution for all the events. I follows the idea of machine learning.
That is to say, we first should have to design a model to express the movement of the object, like what we do with human detection. The movement will be recorded in a form of feature vectors. Then we should have got some training data to train SVM to tell SVM to distinguish the positive event feature vector from the negative event feature vector. Finally we can use this trained SVM to check if the event we are monitoring now is positive or negative. The second approach is preferable if the event can be easily monitored and tracked. But here due to the limited accuracy of human detection module, the supervised learning method seems to be a too challenging task to do. The reason behind is the situation that some of the detected human are not continuous. So this causes gaps of the monitoring of the event, which as a result, makes the object tracking unreliable. Besides, the implementation complexity of the second approach is a great challenge for me. So I choose to use the first method to deal with event detection.

Here we define the people-meet event as the circumstance that two human in the video frame stand so close to each other that their Euclidean distance meet a threshold. This definition may result in a lot of exceptions. Its accuracy greatly rely on the accuracy of the human detection module. So this is one of the limitations of the system. In the system, once the event detector of people-meet is triggered, a text will be shown in the final output frame. It is shown in Figure
As the system do the operation on a frame-to-frame approach, it is extremely difficult for me to check the accuracy for the result frame by frame. Instead, I just watch the video and compare the output result from the original video by eye-watching to check the occurrence of true negative (No human in the original video but output detect with a human there in mistake) and false negative (A human in the original video but fail to detect in the output result). And the resulted comment about the accuracy of the system is listed as below:
1. True negative just rarely happen and the first stage of background subtraction contribute much to such performance. While false negative occurs frequently. This is caused by the limited training set, unreliable background subtraction output and shortage of the algorithms itself.
2. Good accuracy for sparsely distributed human objects, bad in crowded situations. In crowded places, people hide each other which result in the case that most people appear with just partly of their body shown in the video frame. If the detection of crowded place is to be done, a new design of the system and usage of other algorithms should be adopted.
3. Good for human who has a straight standing pose, unable to detect human who are seated due to limited training samples. This is also caused by the limited training images of human. Because all the images that we use are the people with standing poses. We are then unable to detect people sitting or running. This can be improved by using more images to train the system. This is actually a normal disadvantage of supervised learning approach. You have to gain a large amount of training data to ensure the accuracy
4. People-Meet event detector just not works well. It is because the people-meet event itself is a very difficult term to define. If two person stands close to each other, we are just unable to determine whether or not they are meeting with each other or just pass by. This can be solved by using the first approach of event detection and distribution
The SmartSur can do some analysis of the input surveillance video and output with the statistics for reference. Our main task is to deal with the event called people-meet.The SmartSur is designed in a right framework that provides great extensibility. If more effort can be devoted into this system, the SmartSur will definitely be smarter. The aspects that I think this system can be improved on are listed as below.
1. A better training database of more data can be used to train the SVM in the human detection module.
2. A better background subtraction algorithm can be used for that sometimes MOG fail to identify the whole foreground object and may cut it into several parts. This will lead to the failure of the final result of detecting human.
3. The object tracking module can be added into the system. So that more events other than people-meet can be detected. For example the event of people-run that we originally planned to detect can then be completed. Moreover, the total number of people that appeared in the video can also be sketched for the system.
4. The supervised learning method should be used for event classification of the system. This enable the system to have a better performance and functiona
In this project, a smart video surveillance system called SmartSur is developed. It has the basic function of background subtraction, human detection and event detection. It provides the functionality of analyse the input video frames and output some statistics about the video for reference. And the pre-defined event called people-meet can also be tracked in most cases. More work are expected to be done to improve the system on aspects of both efficiency and speed. Besides, its functionality can also be improved if some difficulties like object tracking can be solved. After all, the SmartSur provide a good platform fir video surveillance system development. And it is a good starting point of mine to learn from many of the computer vision techniques like object recognition, human detection and event classification.
[1] M. Piccardi, "Background subtraction techniques: a review," in Systems, Man and Cybernetics, 2004 IEEE International Conference on, 2004, pp. 3099-3104 vol.4.
[2] Cucchiara, R., Piccardi, M., Prati, A.: Detecting Moving Objects, Ghost, and Shadows in Video Streams. IEEE Transactions on, vol 25, pp. 1337-1342, 2003
[3] C. R. Wren, et al., "Pfinder: real-time tracking of the human body," Pattern Analysis and Machine Intelligence, IEEE Transactions on, vol. 19, pp. 780-785, 1997.
[4] D. Koller, J. Webber, T. Huang, J. Malik, G. Ogasawara, B. Rao, and S. Russel, “Towards Robust Automatic Traffic Scene Analysis in Real Time,” Proceedings of the 12th IAPR International Conference on Computer Vision & Image Processing, 1,pp. 126-131, 1994
[5] N. Friedman, S. Russell, “Image Segmentation in Video Sequences: A probabilistic Approach,” In Proc. of the Thirteenth Conference on University in Artificial Intelligence (UAI), 1997
