


Published on Nov 30, 2023
Data Mining For Credit Card Application Processing Project propose an efficient method for the extraction of useful information and processing the credit card applicants based on the data mining algorithms. Processing the credit card applicants has been a focused topic in recent data mining research Many credit card applications need to be processed in a single day.
Therefore an effective method for extracting useful pattern is required. KDD is the step by step process in the discovery of hidden knowledge and new rules from the databases.
For the application processing many data mining algorithms are used such as classification, association rules and query analyzer. Here K-clustering and decision trees are used in detail. Data items are grouped according to logical relationships or consumer preferences. Patterns are formed using clusters which are further assessed with the help of decision trees. The patterns formed from these two methods are then helpful in association rules. All the above algorithms abide to the criteria selected by the credit card issuing authority. The data is presented in the graph format, making the processing better.
The objective of this project is mining the useful data from the databases and applying data mining algorithms for processing the credit card applications based on certain criteria.
The proposed data mining software analyses relationships and patterns in the stored database based on open-ended user queries. Stored data is used to locate data in predetermined groups. The main focus of the project is to reduce the repetitive task and make administrations to maintain the detail’s about a customer who is applied to a credit card. Generates the final report whether the customers who are all eligible to the credit, which keeps track of the customer’s who are selected.
Our project has been organized in the following pattern. During the beginning of the project, first step was to accumulate the background knowledge about data mining. This served as the necessary groundwork for us to work on the application. Subsequently we ventured into the existing techniques used for processing the credit card applications which provided us with various ideas upon which we could improvise, in this phase we studied the K-clustering and decision trees in detail to provide a better result. Our next step was to analyze the software requirement, cost estimation and the project schedule. Next the coding was done using java and SQL server as backend. Finally we have provided references where we collected information about various aspects of the project. These references will be useful in future improvisation of the project.
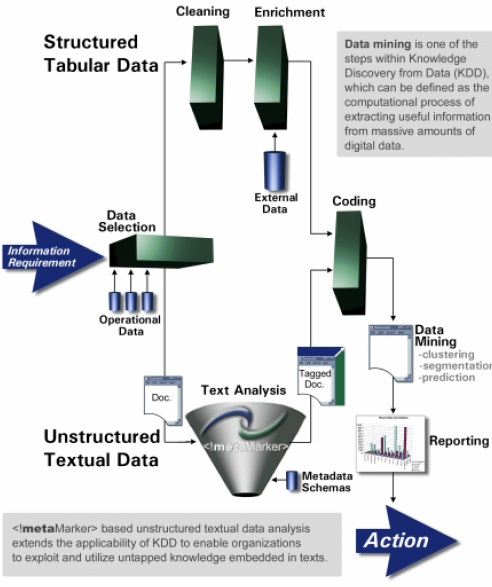
KDD (knowledge discovery in databases) is the non-trivial extraction of implicit, previously unknown and potentially useful knowledge from data. In principle the KDD process consists of six stages:
1. Data selection
2. Cleaning
3. Enrichment
4. Coding
5. Data mining
6. Reporting
The fifth stage is the phase of real discovery. At every stage, the data miner can step back one or more phases; for instance, when in the coding or the data mining phases, the data miner might realize that the cleaning phase is incomplete, or might discover new data and use it to enrich other existing data sets.
The minimum hardware required for the development of the project is:
Processor Type : Pentium IV
Processor Clock Speed : 1.7 GHz
Cache Memory : 1 MB
RAM : 256 MB
Hard Disk Drive : 40 GB
Floppy Disk Drive : 1.44 MB
CD-ROM Drive : 52x
Display Type : SVGA
Key Board : Multimedia
Mouse : 2 Button mouse
Front-end : Java
Back-end : SQL SERVER 2000
The proposed system consists of the following modules.
Data collection – Existing members:
Collect all the needed details of customer who already have an account with the bank and needs to apply for the credit card. Data such as salary, assets etc.
Data storage:
All the collected information from the customers are stored in the database. If new criteria for determining the clusters are needed, the database can be updated. Database contents can be viewed, modified, deleted only by the bank client.
Credit card application process entries:
These entries are for the customers who need a credit card and an account. Credit card detail includes salary, car owned or not, house owned or not etc. Account detail includes name, address, salary etc.
Credit card application data storage:
This module is similar to the second module that is storing all the collected details from the above step.
Loan application:
These entries are collected from the customers who need a loan from the bank. This include account number, amount etc. These entries are also considered in processing the credit card.
Query analyzer:
This module is to extract easily accessible information from the data set using simple query statements. 80 % of the information accessing can be performed in this module.
Data classification based on criteria:
Based on criteria such as salary > 300,000 etc data are classified accordingly. These classified data are used in processing the credit card.
Data clusters through K – Clustering:
Here records of the same type will be close to each other in the data space , they will be living in each others neighborhood . Based on this, the basic concept of K-Clustering is “do as your neighbors do” . The letter K here stands for number of customers (neighbors) we investigate.
Data association through decision trees:
To predict a certain kind of customer behavior, a suitable attribute which gives us more information is chosen. For this attribute a certain threshold is found and the customers are associated accordingly. Repeat the process until we have to find the correct classification.
Result analysis:
Based on the classification the eligible customers for credit card sanctioning are found out and the prediction is also made.
Our work deals with discovery of hidden knowledge, unexpected patterns and new rules from databases. We have done the credit card application processing through k-clusters and decision trees, thus making the process easy and efficient. The processing takes place by considering the applicants data in a day and then evaluating them by different data mining algorithms. We have used data classification, query analyzer, k-clustering, decision trees and association rules. Our study shows that by clustering and decision trees the applicants can be classified effectively according to the needed criteria.
Our performance study shows that different data can be entered and for those data, processing was investigated. Knowledge discovery is the first practical step towards realizing information as a production factor. We have done a step by step process in knowledge discovery and classification is best known. Data mining is important for all organizations that utilize large data sets and we have made our work as accessible as possible.
