


Published on Nov 30, 2023
Enhanced Search Engine Project deals with designing algorithms for summarizing and indexing text files. In case of multimedia files the meta data files are created manually by the programmers.In this system the searching is not done at the run time as indexing is done before hand. This concept of meta-data search is a new technique and is faster. In this phase, meta data files are created for the text documents which contain all the key-words.
Phase 2 deals with the retrieval of files and displaying them to the user. This phase of the project was dealt by creating a User Interface. This user friendly interface was structured using applets and adding various components into it. This phase mainly deals with the acceptance of key-words from the user and displaying the corresponding results.
In Phase 3 folders would be replaced by a new construct called a library. A library is a virtual folder that intelligently gathers information about files on the system and presents them to the users. The concept of folders ceases to exist. Instead, the users are privileged enough to view similar files together irrespective of their location in the physical memory. This enables retrieval of files based on various parameters. This concept is named as CAROUSEL VIEW after the proposed system with the same name to be launched by the Microsoft’s Windows Longhorn which is a complete revolution in itself.
The current project is divided into three inter-dependent phases.
PHASE 1: Summarizing text files.
PHASE 2: Retrieving and display of files
PHASE 3: Developing Carousel view
The minimum hardware required for the development of the project is:
Processor Type : Pentium -IV
Speed : 2.4 GHZ
Ram : 128 MB RAM
Hard disk : 20 GB HD
�� Considering the robustness, flexibility, compatibility and many other features we decided to use Java jdk as a platform for building our system.
�� Considering the user friendliness and ease with which it can be operated we have used Windows OS as a platform for building our system.
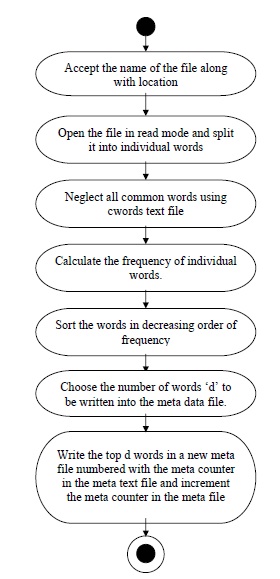
Phase 1 deals with designing of algorithms for summarizing text files. This phase also involves designing algorithms for converting .doc and .pdf files to .txt format. In this system, the searching is not done at the run time as indexing is done before hand. That is how our system is different from other conventional search engines. Here we introduce a concept of meta-data which we shall look in detail.
Phase 1 deals with the following concepts:
• CONCEPT OF META DATA
• CONCEPT OF KEY WORDS
• COMMON WORD ELIMINATION
• CREATION AND NAMING OF META DATA FILES
• CONTENT OF META DATA FILES
The steps followed in the summarizing algorithm used are explained in the following activity diagram.
As we have been mentioning throughout this project, this content based desktop search which we developed is different from the traditional ones. We started off with an aim to create a search system which is different from other traditional ones and also to display the retrieved files in such a manner that is different from other search engines. We did succeed in this mission by accomplishing this task of devising a new technique for retrieving files and also displaying them in a completely new format which was never done before. Here we incorporate the concept of “meta-data”. Although search engines are implemented using this concept it has not yet flooded the market completely. As said earlier, the concept of meta-data is not entirely new, but our approach towards the concept gives a new dimension.
Let us see how our project was different and what our approach was. Firstly, our desktop search is different from the traditional search engines in the fact that the search is done beforehand and not during the run time. Secondly meta data files are created for every text document in the system.
• Since we create a meta-data file for every text document in the system, when the key-word is entered, instead of opening an original file each time and verifying its entire content, a meta data file for the corresponding file will alone be opened and verified for the presence of given key-words. Here since we are not dealing with the original files as such and the meta data files are of smaller size, the time taken might be slightly lesser compared to the normal traditional search, but the time difference might be minimal and may not noticeable.
• This method of retrieving files is far more efficient and effective than that of traditional methods of retrieval. This concept can be very advantageous if there are vast amount of data and large number of files in the system as retrieval can be done in an easier fashion.
Till now, we have only discussed about the meta-data module and retrieval. Now we shall discuss upon the methodology used to display these retrieved files to the user. We baptized a view for the display of files as “Carousel View”. This is named after the proposed system with the same name to be launched by the Microsoft’s “Windows Longhorn” which is a complete revolution in itself.
