


Published on Jan 09, 2026
ZFS (Zettabyte FileSystem) is a file system designed by Sun Microsystems for the Solaris Operating System. ZFS is a 128-bit file system, so it can address 18 billion billion times more data than the 64-bit systems ZFS is implemented as open-source filesystem, licensed under the Common Development and Distribution License (CDDL).
The features of ZFS include support for high storage capacities, integration of the concepts of file system and volume management, snapshots and copy-on-write clones, continuous integrity checking and automatic repair, RAID-Z etc. Additionally, Solaris ZFS implements intelligent prefetch, performing read ahead for sequential data streaming, and can adapt its read behavior on the fly for more complex access patterns.
To eliminate bottlenecks and increase the speed of both reads and writes, ZFS stripes data across all available storage devices, balancing I/O and maximizing throughput. And, as disks are added to the storage pool, Solaris ZFS immediately begins to allocate blocks from those devices, increasing effective bandwidth as each device is added. This means system administrators no longer need to monitor storage devices to see if they are causing I/O bottlenecks.
Anyone who has ever lost important files, run out of space on a partition, spent weekends adding new storage to servers, tried to grow or shrink a file system, or experienced data corruption knows that there is room for improvement in file systems and volume managers. Solaris ZFS is designed from the ground up to meet the emerging needs of a general purpose local file system that spans the desktop to the data center. Solaris ZFS offers a dramatic advance in data management with an innovative approach to data integrity, near zero administration, and a welcome integration of file system and volume management capabilities.
The centerpiece of this new architecture is the concept of a virtual storage pool which decouples the file system from physical storage in the same way that virtual memory abstracts the address space from physical memory, allowing for much more efficient use of storage devices. In Solaris ZFS, space is shared dynamically between multiple file systems from a single storage pool, and is parceled out of the pool as file systems request it. Physical storage can be added to or removed from storage pools dynamically, without interrupting services, providing new levels of flexibility, availability, and performance.
And in terms of scalability, Solaris ZFS is a 128-bit file system. Its theoretical limits are truly mind-boggling — 2128 bytes of storage, and 264 for everything else such as file systems, snapshots, directory entries, devices, and more. And ZFS implements an improvement on RAID-5, RAID-Z, which uses parity, striping, and atomic operations to ensure reconstruction of corrupted data. It is ideally suited for managing industry standard storage servers like the Sun Fire 4500.
ZFS is more than just a file system. In addition to the traditional role of data storage, ZFS also includes advanced volume management that provides pooled storage through a collection of one or more devices. These pooled storage areas may be used for ZFS file systems or exported through a ZFS Emulated Volume (ZVOL) device to support traditional file systems such as UFS. ZFS uses the pooled storage concept which completely eliminates the antique notion of volumes. According to SUN, this feature does for storage what the VM did for the memory subsystem. In ZFS everything is transactional , i.e., this keeps the data always consistent on disk, removes almost all constraints on I/O order, and allows for huge performance gains.
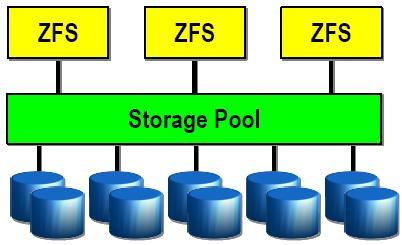
Unlike traditional file systems, which reside on single devices and thus require a volume manager to use more than one device, ZFS file systems are built on top of virtual storage pools called zpools. A zpool is constructed of virtual devices (vdevs), which are themselves constructed of block devices: files, hard drive partitions, or entire drives, with the last being the recommended usage. Block devices within a vdev may be configured in different ways, depending on needs and space available: non-redundantly (similar to RAID 0), as a mirror (RAID 1) of two or more devices, as a RAID-Z group of three or more devices, or as a RAID-Z2 group of four or more devices.
Besides standard storage, devices can be designated as volatile read cache (ARC), nonvolatile write cache, or as a spare disk for use only in the case of a failure. Finally, when mirroring, block devices can be grouped according to physical chassis, so that the file system can continue in the face of the failure of an entire chassis.
Storage pool composition is not limited to similar devices but can consist of ad-hoc, heterogeneous collections of devices, which ZFS seamlessly pools together, subsequently doling out space to diverse file systems as needed. Arbitrary storage device types can be added to existing pools to expand their size at any time. If high-speed solid-state drives (SSDs) are included in a pool, ZFS will transparently utilize the SSDs as cache within the pool, directing frequently used data to the fast SSDs and less-frequently used data to slower, less expensive mechanical disks.
The storage capacity of all vdevs is available to all of the file system instances in the zpool. A quota can be set to limit the amount of space a file system instance can occupy, and a reservation can be set to guarantee that space will be available to a file system instance.
This arrangement of pool will eliminate bottlenecks and increase the speed of reads and writes, Solaris ZFS stripes data across all available storage devices, balancing I/O and maximizing throughput. And, as disks are added to the storage pool, Solaris ZFS immediately begins to allocate blocks from those devices, increasing effective bandwidth as each device is added. This means system administrators no longer need to monitor storage devices to see if they are causing I/O bottlenecks.
An advantage of copy-on-write is that when ZFS writes new data, the blocks containing the old data can be retained, allowing a snapshot version of the file system to be maintained. ZFS snapshots are created very quickly, since all the data composing the snapshot is already stored; they are also space efficient, since any unchanged data is shared among the file system and its snapshots.
Writeable snapshots ("clones") can also be created, resulting in two independent file systems that share a set of blocks. As changes are made to any of the clone file systems, new data blocks are created to reflect those changes, but any unchanged blocks continue to be shared, no matter how many clones exist.
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
