


Updated on May 29, 2026
Web clustering Engines are emerging trend in the field of information retrieval. They organize search results by topic, thus offering a complementary view to the flat ranked list returned by the conventional search engines.
The search results returned by traditional search engines on different subtopics or meanings of a query will be mixed together in the list so that the user may have to sift through a large number of irrelevant items to locate those of interest. The Web clustering engines categorize the search results into different hierarchical groups/clusters and display those cluster labels.
Hence the user can locate the desired document very fast. In this seminar we discuss different phases in the implementation of web clustering engines in detail and also incorporate some of the web clustering algorithms, their advantages and issues. We will familiarize some currently using web clustering engines. Some future research directions are also presented.
Clustering is the act of grouping similar object into sets. The distance between the objects in the same cluster(inter-cluster variations) should be minimum and the distance between objects in different clusters(intra-cluster variations) should be maximum. In the web search context, organizing web pages (search results) into groups, so that different groups correspond to different user needs. In 1979 Van Rijsbergen introduced the concept Cluster Hypothesis in the field of information retrieval. It states that “Closely related documents tend to be relevant to the same requests.” Web Clustering Engines are the systems that perform clustering of web search results. This systems group the results returned by a search engine into a hierarchy of labeled clusters (also called categories).
Web Clustering Engines organize search results by topic, thus offering a complementary view to the flat ranked list returned by the conventional search engines.
Main advantages of the cluster hierarchy is that:
It makes for shortcuts to the items that relate to the same meaning. Since Web Clustering Engines group the search results having the same meaning within same cluster it is very easy for the user to find similar documents. Hence the search time will be less.
It allows better topic understanding. Since Web Clustering Engines give a high level view of the query, it is useful for informational searches in unknown or dynamic domains.
It favors systematic exploration of search results. A clustering engine summarizes the content of many search results in one single view on the first result page, the user may review hundreds of potentially relevant results without the need to download and scroll to subsequent pages.
A clustering engine tries to address the limitations of current search engines by providing clustered results as an added feature to their standard user interface.
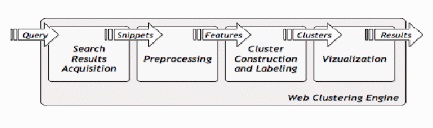
Practical implementations of Web search clustering engines will usually consist of four general components: search results acquisition, input preprocessing, cluster construction, and visualization of clustered results, all arranged in a processing pipeline.
The task of the search results acquisition component is to provide input for the rest of the system. Based on the query, the acquisition component must deliver 50 to 500 results, each of which should contain a title, a contextual snippet, and the URL pointing to the full text being referred to. The source of search results can be any public search engines, such as google, yahoo etc. Clustering applied to this smaller set of documents ,returned by the conventional search engines, in response to the query. The most elegant way of fetching results from such search engines is by using application programming interfaces(APIs) these engines provide.
Input preprocessing is a step that is common to all search results clustering systems. Its primary aim is to convert the contents of search results (output by the acquisition component) into a sequence of features used by the actual clustering algorithm. Steps for feature extraction are, Language identification, Tokenization, Stemming, Selection of features.
Clustering engines that support multilingual content must perform initial language recognition on each search result in the input. During the tokenization step, the text of each search result gets split into a sequence of basic independent units called tokens, which will usually represent single words, numbers, symbols and so on .Tokenization becomes much more complex for languages where white spaces are not present (such as Chinese) or where the text may switch direction (such as an Arabic text, within which English phrases are quoted).
The aim of stemming is to remove the inflectional prefixes and suffixes of each word and thus reduce different grammatical forms of the word to a common base form called a stem. For example, the words connected, connecting and interconnection would be transformed to the word connect .Here connect is the stem. Last but not least, the preprocessing step needs to extract features for each search result present in the input. Features are atomic entities by which we can describe an object and represent its most important characteristic to an algorithm. When looking at text, the most intuitive set of features would be simply words of a given language. But this is not the only possibility.
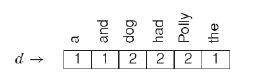
The features can vary from single words and fixed-length tuples of words (n-grams) to frequent phrases (variable-length sequences of words), and very algorithm-specific data structures, such as approximate sentences. One method for representing a text is Vector Space model(VSM). A document d is represented in the VSM as a vector [wt0 , wt1 , . . .wtn], where t0, t1, . . . tn is a global set of words (features) and wti expresses the weight (importance) of feature ti to document d. Weights in a document vector typically reflect the distribution of occurrences of features in that document. For example, a term vector for the phrase “Polly had a dog and the dog had Polly” could appear as shown below (weights are simply counts of words, articles are rarely specific to any document and normally would be omitted).
The set of search results along with their features, extracted in the preprocessing step, are given as input to the clustering algorithm, which is responsible for building the clusters and labeling them. There are a number of algorithms available for clustering. We can classify them into two different categories, Data centric and Description aware. In search results clustering users are the ultimate consumers of cluster. Hence the created clusters should be aptly labeled. The labels should be unique, unambiguous, comprehensive and sensible to the content. An inefficiently labeled cluster is useless eventhough it contains closely related, relevant documents.
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
