


Updated on May 29, 2026
The development of 3D video in recent years realizes 3D surface capturing of human in motion as is. In this paper, we introduce 3D human sensing algorithms based on 3D video. Since 3D video capturing does not require the object to attach special markers, we can capture the original information such as body motion or viewing directions without any disturbance caused by the sensing system itself.
The development of 3D video technology in recent years has realized 3D shape capturing of the object in motion as is [3] [1] [2] [4]. Since 3D video is captured by conventional 2D cameras, the object is not required to attach special markers nor wear a special costume. This is a clear advantage against other motion capturing technologies, and therefore 3D video is suitable for 3D digital archiving of human motion including intangible cultural assets. However, 3D video itself is merely a non-structured 3D surface data as same as pixel streams of conventional 2D video. In this paper we show how we can sense the human activity from raw 3D video.
The term “3D video” or “free viewpoint video” includes two different approaches in literature. One approach is called “model-based” methods which reconstruct 3D shapes of the object first and then render them as same as CG[2][4]. The other approach is “image-based” methods which interpolate a 2D image at a virtual camera position directly from 2D multi-viewpoint images. For 3D human sensing, modelbased approaches are suitable since image-based methods do not produce 3D information. The 3D shape estimation done in the model-based approaches is a classic but open problem in computer vision.
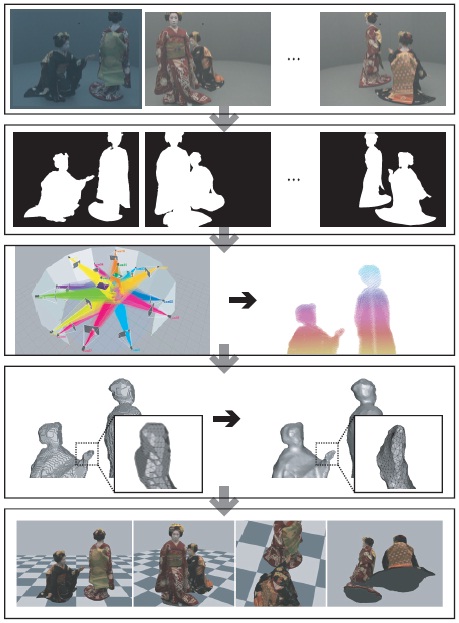
Figure 1. 3D video capturing flow. A set of multi-viewpoint silhouettes given by the multi-viewpoint object images produces a rough estimation of the object shape called “visual hull”, and it will be refined based on the photo-consistency between the input images. Texture-mapped 3D surface can produce virtual images from arbitrary viewpoints.
This is an ill-posed problem to estimate the original 3D shape from its 2D projections. In recent years, many papers have proposed practical algorithms which integrates conventional stereo matching and shape-from-silhouette technique to produce full 3D shape as photo hull. We assume that we have the optimal photo hull of the object and use it as the 3D real surface of the object[8][5]. Figure 1 shows our 3D video capturing scheme. The top and second rows show an example of multi-viewpoint input images and object regions in them respectively. The visual hull of the object is then computed using multi-viewpoint silhouettes as shown in the third row, and we refine it through photoconsistency optimization and obtain the optimal 3D surface of the object(the fourth row). Finally, we map textures on the 3D surface. The bottom row shows sample rendering of the final 3D surface estimated from the multi-viewpoint images shown by the top row.
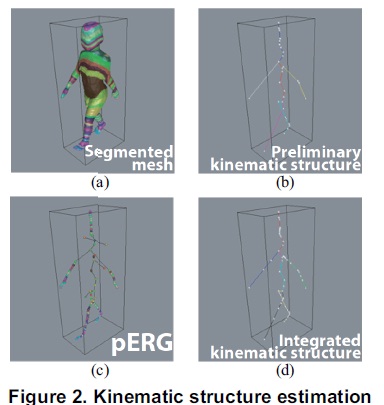
In this section we introduce an algorithm to estimate the kinematic structure of an articulated object captured as 3D video. The input is a time-series of 3D surfaces, and we build up the kinematic structure purely from the input data. Let Mt denote the input 3D surface at time t (Figure 2(a)). We first build the Reeb graph[6] of Mt as shown in Figure 2(b). Reeb graph is computed based on the integral of geodesic distances on Mt and gives a graph structure similar to the kinematic structure. Figure 2(a) shows the surface segmentation based on the integral of geodesic distances.
However, the definition of Reeb graph does not guarantee to all the graph edges pass inside of Mt and some edges can go outside. So we modify such parts of the Reeb graph to make sure that it will be encaged by Mt . Figure 2(c) shows the modified graph which we call pERG (pseudo Endoskeleton Reeb Graph). We start from building pERGs at every frame, then we select “seed” pERGs which have no degeneration of their body parts. Here we use a simple assumption that a seed pERG should have five branches since we focus on the human behavior.
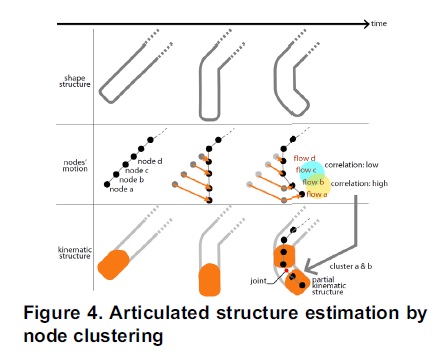
Then we do pERG-to-pERG fitting from seed frames to their neighbors. We deform the seed frame so as to fit to its neighbors, and repeat it until the fitting error exceeds a certain threshold. This process gives topologically isomorphic interval for each seed frame as shown in the top of Figure 3. In each interval, we apply node clustering to find articulated structure (Figure 4). Finally, we integrate articulated structures estimated at all intervals into an unified kinematic structure as shown in the bottom of Figure 3. Figure 2(d) and 5 show the final unified kinematic structure estimated purely from the input 3D surface sequence.
First we introduce our visibility definition on the model M(p) using the collision detection between body parts. Since collided regions cannot be observed from any cameras in general, we detect such regions as shown in Figure 8. The color indicates the distance between a point to its closest surface of other parts. Using this distance and visibility, we define the reliability of M(p) as
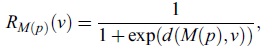
where v denotes a vertex in M(p), and d(M(p),v) denotes the distance from v to the closest point of other parts. Visibility of the Observed Surface Next we introduce the visibility of the observed surface Mt . Since Mt is estimated from the multi-viewpoint images, the vertices on Mt can be categorized by the number of the cameras which can observe it. If one or less camera can observe a vertex v, v cannot be photo-consistent and the position of v is interpolated by its neighbors. On the other hand, if two or more cameras can observe v, v should be photo-consistent and its 3D position is estimated explicitly by the stereo-matching. So we can conclude that the number of observable cameras of v tells the reliability on its 3D position.
We introduced human activity sensing algorithms from 3D video. Our algorithms cover (1) global kinematic structure, (2) complex motion estimation, and (3) detailed face and eye direction estimation. These are all non-contact sensing and do not require the object to use neither a special marker nor a costume. This is a clear advantage of our 3D video based sensing.
[1] T. Kanade, P. Rander, and P. J. Narayanan. Virtualized reality: Constructing virtual worlds from real scenes. IEEE Multimedia, pages 34–47, 1997.
[2] T. Matsuyama, X. Wu, T. Takai, and S. Nobuhara. Real-time 3d shape reconstruction, dynamic 3d mesh deformation and high fidelity visualization for 3d video. CVIU, 96:393–434, Dec. 2004.
[3] S. Moezzi, L.-C. Tai, and P. Gerard. Virtual view generation for 3d digital video. IEEE Multimedia, pages 18–26, 1997.
[4] J. Starck and A. Hilton. Surface capture for performance based animation. IEEE Computer Graphics and Applications, 27(3):21–31, 2007.
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
