


Updated on Mar 21, 2026
A smart camera performs real-time analysis to recognize scenic elements. Smart cameras are useful in a variety of scenarios: surveillance, medicine, etc.We have built a real-time system for recognizing gestures. Our smart camera uses novel algorithms to recognize gestures based on low-level analysis of body parts as well as hidden Markov models for the moves that comprise the gestures.
These algorithms run on a Trimedia processor. Our system can recognize gestures at the rate of 20 frames/second. The camera can also fuse the results of multiple cameras
Recent technological advances are enabling a new generation of smart cameras that represent a quantum leap in sophistication. While today's digital cameras capture images, smart cameras capture high-level descriptions of the scene and analyze what they see. These devices could support a wide variety of applications including human and animal detection, surveillance, motion analysis, and facial identification.
Video processing has an insatiable demand for real-time performance. Fortunately, Moore's law provides an increasing pool of available computing power to apply to real-time analysis. Smart cameras leverage very large-scale integration (VLSI) to provide such analysis in a low-cost, low-power system with substantial memory. Moving well beyond pixel processing and compression, these systems run a wide range of algorithms to extract meaning from streaming video.
Because they push the design space in so many dimensions, smart cameras are a leading-edge application for embedded system research.
Although there are many approaches to real-time video analysis, we chose to focus initially on human gesture recognition-identifying whether a subject is walking, standing, waving his arms, and so on. Because much work remains to be done on this problem, we sought to design an embedded system that can incorporate future algorithms as well as use those we created exclusively for this application.
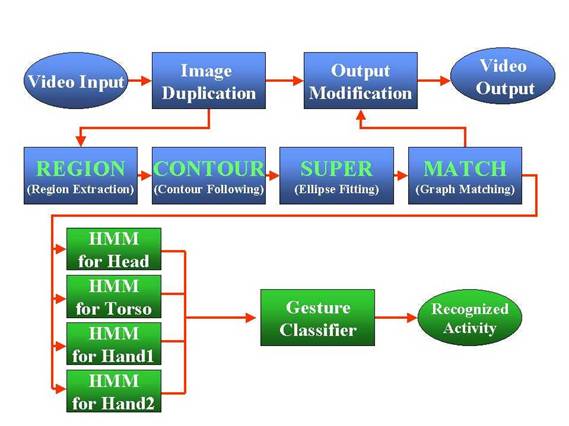
Our algorithms use both low-level and high-level processing. The low-level component identifies different body parts and categorizes their movement in simple terms. The high-level component, which is application-dependent, uses this information to recognize each body part's action and the person's overall activity based on scenario parameters.
The system captures images from the video input, which can be either uncompressed or compressed (MPEG and motion JPEG), and applies four different algorithms to detect and identify human body parts.
Region extraction: The first algorithm transforms the pixels of an image into an M ¥ N bitmap and eliminates the background. It then detects the body part's skin area using a YUV color model with chrominance values down sampled
Nextthe algorithm hierarchically segments the frame into skin-tone and non-skin-tone regions by extracting foreground regions adjacent to detected skin areas and combining these segments in a meaningful way.
Contour following: The next step in the process involves linking the separate groups of pixels into contours that geometrically define the regions. This algorithm uses a 3 ¥ 3 filter to follow the edge of the component in any of eight different directions.
Ellipse fitting: To correct for deformations in image processing caused by clothing, objects in the frame, or some body parts blocking others, an algorithm fits ellipses to the pixel regions to provide simplified part attributes. The algorithm uses these parametric surface approximations to compute geometric descriptors for segments such as area, compactness (circularity), weak perspective invariants, and spatial
relationships.
Graph matching: Each extracted region modeled with ellipses corresponds to a node in a graphical representation of the human body.
A piecewise quadratic Bayesian classifier uses the ellipses parameters to compute feature vectors consisting of binary and unary attributes. It then matches these attributes to feature vectors of body parts or meaningful combinations of parts that are computed offline. To expedite the branching process, the algorithm begins with the face, which is generally easiest to detect.
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
