


Updated on May 29, 2026
A Learning Management System (or LMS) is a software tool designed to manage user learning processes. LMSs go far beyond conventional training records management and reporting. The value-add for LMSs is the extensive range of complementary functionality they offer.
Learner self-service (e.g. self-registration on instructor-led training), learning workflow (e.g. user notification, teacher approval, waitlist management), the provision of on-line learning, on-line assessment, management of continuous professional education, collaborative learning (e.g. application sharing, discussion threads), and training resource management (e.g. instructors, facilities, equipment), are some of the additional dimensions to leading learning management systems. In addition to managing the administrative functions of online learning, some systems also provide tools to deliver and manage instructor-led synchronous and asynchronous online teaching based on learning object methodology.
These systems are called Learning content management systems or LCMSs. An LCMS provides tools for authoring and re-using or re-purposing content as well as virtual spaces for learner interaction (such as discussion forums and live chat rooms). The focus of an LCMS is on learning content. It gives authors, instructional designers, and subject matter experts the means to create and re-use e-learning content more efficiently.
The current learning management systems have a number of drawbacks which hinder their wide acceptance among teachers and students. One of them is the non-availability of free content. LMS’s assume that the content will be put up by users i.e. teachers and students. This leads to the cold start problem. Instructors who begin to make up a course don't have the material to start up. Materials presented may lack coverage of the subject area and thus fail to cater information needs of all students in a class.
On the other hand, students while studying or reading a lecture have to waste a lot of their time in searching for relevant resources from the web. We aim to build a system which solves the above problem to a large extent. The system uses the power of Web to solve the cold start problem. While putting up new course, assignment or a lecture, similar resources would be available from the digital library either by search or by recommendations.
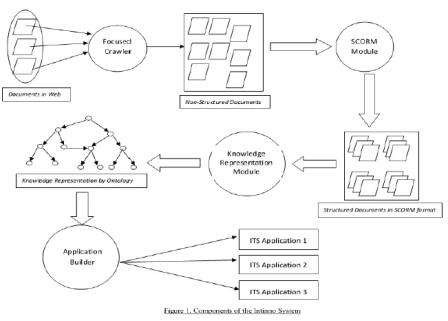
The size of the publicly index able world-wide-web has provably surpassed one billion documents and as yet growth shows no sign of levelling off. Dynamic content on the web is also growing as time-sensitive materials, such as news, financial data, entertainment and schedules become widely disseminated via the web. Search engines are therefore increasingly challenged when trying to maintain current indices using exhaustive crawling. Even using state of the art systems such as Google, which reportedly crawls millions of pages per day, an exhaustive crawl of the web can take weeks. Exhaustive crawls also consume vast storage and bandwidth resources, some of which are not under the control of the search engine.
Focused crawlers aim to search and retrieve only the subset of the world-wide web that pertains to a specific topic of relevance. The ideal focused crawler retrieves the maximal set of relevant pages while simultaneously traversing the minimal number of irrelevant documents on the web. Focused crawlers therefore offer a potential solution to the currency problem by allowing for standard exhaustive crawls to be supplemented by focused crawls for categories where content changes quickly. Focused crawlers are also well suited to efficiently generate indices for niche search engines maintained by portals and user groups, where limited bandwidth and storage space are the norm. Finally, due to the limited resources used by a good focused crawler, users are already using personal PC based implementations.
Ultimately simple focused crawlers could become the method of choice for users to perform comprehensive searches of web-related materials. The major open problem in focused crawling is that of properly assigning credit to all pages along a crawl route that yields a highly relevant document. In the absence of a reliable credit assignment strategy, focused crawlers suffer from a limited ability to sacrifice short term document retrieval gains in the interest of better overall crawl performance. In particular, existing crawlers still fall short in learning strategies where topically relevant documents are found by following off-topic pages.
The credit assignment for focused crawlers can be significantly improved by equipping the crawler with the capability of modeling the context within which the topical materials is usually found on the web. Such a context model has to capture typical link hierarchies within which valuable pages occur, as well as describe off-topic content that co-occurs in documents that are frequently closely associated with relevant pages. The focused crawler for the Intinno system tries to collect the course pages which are rich source of authenticated educational content. Crawling the whole university and then separating out the course pages with the help of a classifier is the simplest solution.
However such a solution is highly in-efficient both in terms of Space and Time required. In another scheme crawler learns the user browsing pattern as the user starts from the University homepage and follows a path which consists of many non-topical pages to reach the pages hosting course content. Hence a context driven crawling scheme which learns the link hierarchies among the pages leading to the relevant page is required to train the crawler.
The first generation of crawlers on which most of the web search engines are based rely heavily on traditional graph algorithms, such as breadth-first or depth-first traversal, to index the web. A core set of URLs are used as a seed set, and the algorithm recursively follows hyperlinks down to other documents. Document content is paid little heed, since the ultimate goal of the crawl is to cover the whole web.
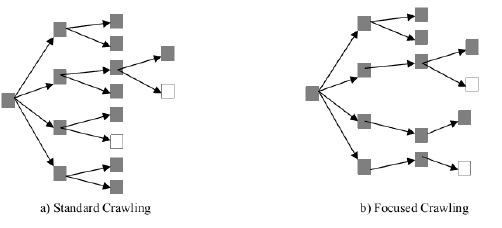
A focused crawler efficiently seeks out documents about a specific topic and guides the search based on both the content and link structure of the web. Figure 2 graphically illustrates the difference between an exhaustive breadth first crawler and a typical focused crawler. A focused crawler implements a strategy that associates a score with each link in the pages it has downloaded . The links are sorted according to the scores and inserted in a queue. A best first search is performed by popping the next page to analyze from the head of the queue. This strategy ensures that the crawler preferentially pursues promising crawl paths. A variety of methods for focused crawling have been developed.
The term focused crawler was first coined by Chakrabarti in, however, the concept of prioritizing unvisited URLs on the crawl frontier for specific searching goals is not new, and Fish-Search by De Bra et al. (1994) and Shark-Search by Hersovici et al. (1998) were some of the earliest algorithms for crawling for pages with keywords specified in the query. In Fish-Search, the Web is crawled by a team of crawlers, which are viewed as a school of fish. If the ‘‘fish’’ finds a relevant page based on keywords specified in the query, it continues looking by following more links from that page. If the page is not relevant, its child links receive a low preferential value. Shark-Search is a modification of Fish-search which differs in two ways: a child inherits a discounted value of the score of its parent, and this score is combined with a value based on the anchor text that occurs around the link in the Web page.
Full Crawl of Wikipedia is possible and can be obtained as a single XML document. However, Full crawl/download may not be necessary and may in fact weaken precision of the search on Digital library. We use a keyword based focused approach described above to limit the pages Being indexed in Wikipedia. Each Wikipedia article can be characterized a lectures or tutorials. While indexing the articles of Wiki more importance should is given to the headings and the sub headings on the page.
Websites in this category will have to be handpicked and will be few in number. Examples of Company websites includes whitepapers, manuals, tutorials obtained from research lab of Companies like IBM, Google, Microsoft, and GE. Handpicked websites of popular corporate training resources like those offering questions/quizzes on C and those offering tutorials like How Stuff Works.
Out of the above mentioned sources, course websites of different Universities are the richest source of learning content.
The advantages of this content are:
1. Since this content is hosted on the University site, under the professor/teacher taking this course, the content is deemed to be authenticated and correct.
2. Also this type of content is used in a real scenario the teach the students and hence is Most relevant to the students. However, along with being the richest source of valid educational content this type of content is most difficult to mine. This is due to the fact that this content is non-structured in nature.
There are following difficulties in mining this content:
Every teacher has his/her own way of hosting the content. Some might be putting up the whole content in a single page while others might be having a more structured Representation of content with different sections for assignments, lectures, etc.
Every University has their own sitemap. A set of rules to reach the course pages starting from University homepage, if designed for a particular university, might not work for every case.
One of the solutions to get the course pages from a particular university would be to crawl the whole university and separate out the course pages from the set of all crawled pages. The separation of course pages will be done by a binary classifier that will be trained on the prior set of course pages that can be obtained with the help of a search engine. However crawling the whole university for course pages would be inefficient both in terms of Time and Space required. Hence we need a focused crawling technique to efficiently mine relevant course pages starting from the university homepage.
Particular emphasis is given to learning focused crawlers capable of learning not only the content of target pages but also paths leading to target pages. In fact, learning crawlers perform a very difficult task: they attempt to learn web crawling patterns leading to relevant pages possibly through other not relevant pages thus increasing the probability of failure. But, with a good crawling strategy, it seems to be possible to build crawlers that can rather quickly obtain a significant portion of the hot pages. Normally, a document relevant to a specific topic frequently contains explicitly a set of topic-specific keywords. For example, a TCP/IP document often contains keywords “tcp, ip, header, protocol”, etc. Therefore, the lexical keywords are a significant factor. In this paper, the user needs to specify these keywords before his/her topic-specific browsing.
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
