


Published on Feb 21, 2020
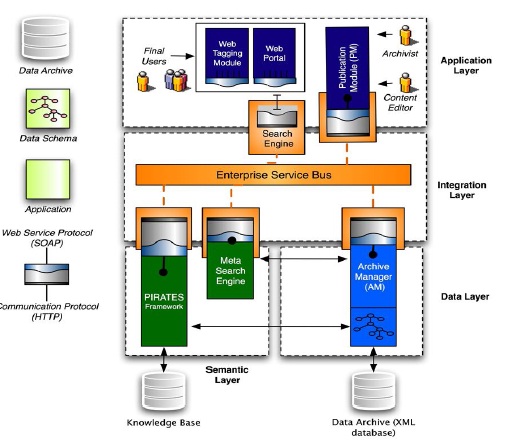
Semantic Digital Library propose a service-oriented architecture that explicitly includes a semantic layer which provides primitive services to the applications built on top of the digital library. As part of this layer, a specific component is described: the PIRATES framework.
This module assists end users to complete several tasks concerning the retrieval of the most relevant content with respect to a description of their information needs (a search query, a user profile, etc.). Techniques of user modeling, adaptive personalization, and knowledge representation are exploited to build the PIRATES services in order to fill the gap existing between traditional and semantic digital libraries. we are designing and developing a digital platform capable of maintaining the semantic meaning of each digital object and its content, of maintaining its origin and authenticity, and of retaining its interrelatedness
This layer exposes its services to the user applications through the Enterprise Service Bus located in the Integration layer. Two main components characterize the Semantic layer:
PIRATES Framework, which communicates with a Knowledge Base in order to retrieve or suggest potentially relevant information from the archives. This framework provides primitive services to automatically classify, annotate and recommend specific content using techniques based on natural language processing. PIRATES is composed of three components, a Cognitive Filtering Tools module, an Automatic Tagger, and a Knowledge Base Builder.
Meta Search Engine, which exploits the document annotations provided by PIRATES in order to recommend similar contents with respect to those retrieved by a traditional search engine fulfilling user queries. This module can also be used for refining a user query which has not provided enough results (query reformulation). The presence of the Semantic Layer is aimed at improving the information access mechanism by empowering its environment by semantic services.
Tagging is a textual annotation technique based on meta-data information (i.e., tags). A tag is a keyword users use to annotate a content, in order to organize knowledge, describe it, correlate it with other contents, or simply to retrieve it easily in future searches. The tagging activity may be manual if it is provided by a human user, or automatic if is it generated by a dedicated software. Archivists can employ tags differently because they can be guided by different tasks. Typically, tagging is used with the explicit intent of:
1. classifying content by means of a corpus of concepts that are familiar to the archivist (e.g., taxonomies, thesauri, or any bag of keywords representing meaningful categories for him/her)
2. summarizing resource content by means of a short list of keywords representing the user-generated content description
3. expressing a polarity judgment about a content by means of proper adjectives provided as tags (e.g., “sad”, “wonderful”)
4. correlating tagged resources with people and their skills such as the level of expertise, the reputation, or the importance of a person mentioned in the resource content (e.g.,“guru”, “geek”, “vip”, “bill-gates”, etc.)
5. creating dichotomous classification criteria in order to describe resources as belonging or not belonging to a particular category (e.g., “clinical”/“not-clinical”, “statistical”/“not-statistical’, “accepted”/“rejected”, and so on)
6. providing temporal information to a resource, for example annotating the date of an event related to that resource.
To some extent, all these forms of tagging express a classification intent targeted to establish effective schemata for organizing the knowledge and facilitating content retrieval. Tagging allows users to determine suitable labels for their resources freely without relying on any predetermined vocabulary or hierarchy . Moreover, tags can be very effective for serendipitous browsing of a digital archive of documents (or bookmarks) in order to find relevant information.
Hence people tag the content with their own vocabulary and ultimately their mental models in order to facilitate the process of recall. Besides with these potential benefits, manual tags suffer with some of notable limitations
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
