


Published on Feb 21, 2020
The rate of improvement in microprocessor speed exceeds the rate of improvement in DRAM memory speed — each is improving exponentially, but the exponent for microprocessors is substantially larger than that for DRAMs.
The difference between diverging exponentials also grows exponentially. Main-memory access has therefore become a performance bottleneck for many computer applications; a phenomenon that is widely known as the “memory wall.”
This report focuses on how research around the MonetDB database system has led to a redesign of database architecture in order to take advantage of modern hardware, and in particular to avoid hitting the memory wall. This encompasses (i) a redesign of the query execution model to better exploit pipelined CPU architectures and CPU instruction caches; (ii) the use of columnar rather than row-wise data storage to better exploit CPU data caches; (iii) the design of new cache-conscious query processing algorithms; and (iv) the design and automatic calibration of memory cost models to choose and tune these cache-conscious algorithms in the query optimizer.
The "memory wall" is the growing disparity of speed between CPU and memory outside the CPU chip. An important reason for this disparity is the limited communication bandwidth beyond chip boundaries. While CPU speed improved at an annual rate of 55%, memory speed only improved at 10%. Given these trends, it was expected that memory latency would become an overwhelming bottleneck in computer performance. The equation for the average time to access memory, where tc and tm are the cache and DRAM access times and p is the probability of a cache hit: some conservative assumptions are made:.
tavg = p × tc + (1 – p) × tm
First assumption is that the cache speed matches that of the processor, and specifically that it scales with the processor speed. This is certainly true for on-chip cache, and allows to easily normalize all the results in terms of instruction cycle times (essentially saying tc = 1 CPU cycle). Second, assumption is that the cache is perfect. That is, the cache never has a conflict or capacity miss; the only misses are the compulsory ones. Thus (1-p) is just the probability of accessing a location that has never been referenced before. Now, although (1-p) is small, it isn’t zero.
Therefore as tc and tm diverge, tavg will grow and system performance will degrade. In fact, it will hit a wall. In most programs, 20-40% of the instructions reference memory. For the sake of argument let’s take the lower number, 20%. That means that, on average, during execution every 5th instruction references memory. We will hit the wall when tavg exceeds 5 instruction times. At that point system performance is totally determined by memory speed; making the processor faster won’t affect the wall-clock time to complete an application.
Vertical storage: Whereas traditionally, relational database systems store data in a row-wise fashion (which favors single record lookups), MonetDB uses columnar storage which favors analysis queries by better using CPU cache lines.
Bulk query algebra: Much like the CISC versus RISC idea applied to CPU design, the MonetDB algebra is deliberately simplified with respect to the traditional relational set algebra to allow for much faster implementation on modern hardware.
Cache-conscious algorithms: The crucial aspect in overcoming the memory wall is good use of CPU caches, for which careful tuning of memory access patterns is needed. This called for a new breed of query processing algorithms, of which radix-partitioned hash-join is illustrated in some detail.
Memory access cost modeling: For query optimization to work in a cache-conscious environment, a methodology was developed for creating cost models that takes the cost of memory access into account. In order to work on diverse computer architectures, these models are parameterized at runtime using automatic calibration techniques.
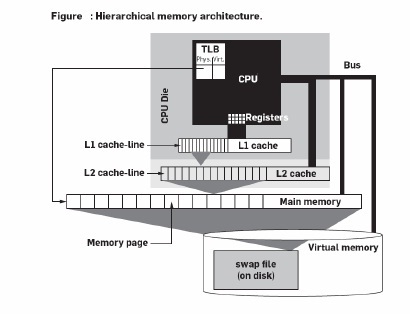
The main memory of computers consists of dynamic random access memory (DRAM) chips. While CPU clock-speeds have been increasing rapidly, DRAM access latency has hardly improved in the past 20 years. Reading DRAM memory took 1–2 cycles in the early 1980s, currently it can take more than 300 cycles. Since typically one in three program instructions is a memory load/store, this “memory wall” can in the worst case reduce efficiency of modern CPUs by two orders of magnitude. Typical system monitoring tools (top, or Windows Task manager) do not provide insight in this performance aspect, a 100% busy CPU could be 95% memory stalled. To hide the high DRAM latency, the memory hierarchy has been extended with cache memories (cf., Figure 1), typically located on the CPU chip itself.
The fundamental principle of all cache architectures is reference locality, i.e., the assumption that at any time the CPU repeatedly accesses only a limited amount of data that fits in the cache. Only the first access is “slow,” as the data has to be loaded from main memory, i.e., a compulsory cache miss. Subsequent accesses (to the same data or memory addresses) are then “fast” as the data is then available in the cache.
This is called a cache hit. The fraction of memory accesses that can be fulfilled from the cache is called cache hit rate. Cache memories are organized in multiple cascading levels between the main memory and the CPU. They become faster, but smaller, the closer they are to the CPU. In the remainder we assume a typical system with two cache levels (L1 and L2). However, the discussion can easily be generalized to an arbitrary number of cascading cache levels in a straightforward way. In practice, cache memories keep not only the most recently accessed data, but also the instructions that are currently being executed. Therefore, almost all systems nowadays implement two separate L1 caches, a read-only one for instructions and a read-write one for data. The L2 cache, however, is usually a single “unified” read-write cache used for both instructions and data.
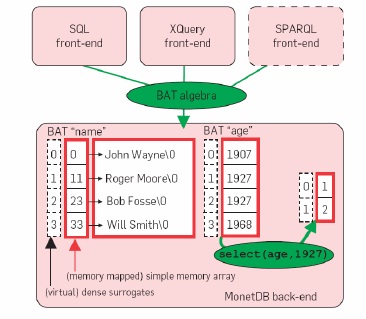
The storage model deployed in MonetDB is a significant deviation of traditional database systems. It uses the decomposed storage model (DSM),8 which represents relational tables using vertical fragmentation, by storing each column in a separate <surrogate, value> table, called binary association table (BAT). The left column, often the surrogate or object-identifier (oid), is called the head, and the right column tail. MonetDB executes a low-level relational algebra called the BAT algebra. Data in execution is always stored in (intermediate) BATs, and even the result of a query is a collection of BATs.
Figure 2 shows the design of MonetDB as a back-end that acts as a BAT algebra virtual machine, with on top a variety of front-end modules that support popular data models and query languages (SQL for relational data, XQuery for XML). BAT storage takes the form of two simple memory arrays, one for the head and one for the tail column (variable-width types are split into
| Are you interested in this topic.Then mail to us immediately to get the full report.
email :- contactv2@gmail.com |
