


Published on Nov 30, 2023
We all know what the abstract of an article is: a short summary of a document, often used to preselect material relevant to the user. The medium of the abstract and the document are the same, namely text. In the age of multimedia, it would be desirable to use video abstracts in very much the same way: as short clips containing the essence of a longer video, without a break in the presentation medium. However, the state of the art is to use textual abstracts for indexing and searching large video archives. This media break is harmful since it typically leads to considerable loss of information. For example it is unclear at what level of abstraction the textual description should be; if we see a famous politician at a dinner table with a group of other politicians, what should the text say? Should it specify the names of the people, give their titles, specify the event, or just describe the scene as if it were a painting, emphasizing colors and geometry? An audio-visual abstract, to be interpreted by a human user, is semantically much richer than a text. We define a video abstract to be a sequence of moving images, extracted from a longer video, much shorter than the original, and preserving the essential message of the original.
With the rapid development of the digital-media industry, the huge video datasets captured by various resources such as webcams, surveillance cameras, are growing at an explosive speed. The amount of captured video is growing with the increased numbers of video cameras, especially the increase of millions of surveillance cameras that operate 24 hours/day.
In most site-seeing surveillance videos, we often observe large amounts of free space in the scene backgrounds, where no active objects move at all. It is time consuming to review entire, lengthy videos, captured by surveillance cameras, to find interesting objects, since most surveillance videos contain only a limited number of important events. Hence, end users often prefer briefer, condensed representations of long video sequences in surveillance videos. This is generally referred as video synopsis or abstraction. It is memory intensive to store and transfer the entire captured videos while retaining less important objects; thus, video synopsis can effectively reduce memory storage for large video datasets.
The main objective of this project is to develop a software system to condense the given surveillance video by preserving the essential activities. The activity in the video is condensed into a shorter period by simultaneously showing multiple activities, even when they originally occurred at different times. The summary will be in the video format with reduced size containing the actions present in original video.
The proposed system analyzes the video for interesting events and records an object-based description of the video. This description lists, for each camera, the interesting objects, their duration, their location, and their appearance. The reduction of the original video to an object-based representation enables a fast response to queries. After a user query about a second (shorter) time period, the requested abstract video is generated having only objects from the desired time period. A two-phase process is used for synopsis of video, is shown in Figure 1.
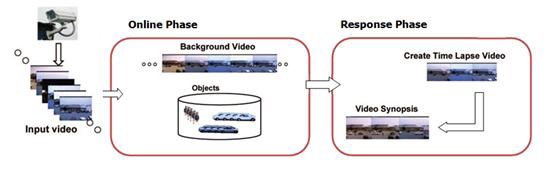
The steps can be summarized as follows.
This phase can be done in real time.
The background for each time can be computed using a temporal median over a few minutes before and after each frame. For example, median over 3 minutes.
Background subtraction is combined together with min-cut to get smooth segmentation of foreground objects
All detected objects, represented as tubes in the space time volume, are stored in a queue awaiting user queries.
This phase constructs a synopsis according to a user query. This phase may take a few minutes, depending on the amount of activity in the time period of interest. This phase includes the following:
Background changes are usually caused by day-night differences, but can also be a result of an object that starts (stops) moving.
Video synopsis is less applicable for a video with already dense activity where all locations are active all the time. An example is a camera in a busy train station. Future work can involve simultaneous display of detected activities. In some cases, the video so obtained is very condensed with objects and events, making it difficult for a user to search for any particular object.
Currently, proposed method works on videos with static backgrounds. It can be extended to handle videos captured by moving cameras. This is a challenging aspect, due to the dynamic backgrounds, and the different types of camera motion, such as panning, zooming, and jittering, etc. It can also be then extended to use video search tools for presenting relevant events first.
We have captured 3 videos and used it as our dataset. Hall.avi, Mall.avi and College.avi. The results are summarized in Table 1. Fig 2 illustrates the indoor scenario captured in a hall. This is taken in a controlled environment. The empty frames in the scenarios are removed in the final output. The length of the video is 3:10 min. Snapshots of public area, a shopping mall surveillance video, are shown in Fig 3. This is an example for uncontrolled environment. As the crowd cannot be predicted. Here a video of length 0:16min was taken for processing. In Fig 4, the snapshots of the surveillance video captured at the college entrance are depicted. This video recording illustrates an outdoor scenario, which can be crowded at peak hours. This video is of length 2:29 min.




Video synopsis is a useful tool for summarizing long surveillance videos captured by digital cameras. It has been proposed as an approach for condensing the activity in a video into a very short time period. This condensed representation can enable efficient access to activities in video sequences and can enable effective indexing into the video. This enables fast browsing of surveillance video by bringing dynamic events widely separated in time closer together.
Video synopsis can make surveillance cameras more useful by giving the viewer the ability to view summaries of endless video stream. Video Synopsis summarizes hours of surveillance video recordings into a short "brief" that takes only minutes to review. It filters out the empty frames present in the input surveillance video and provides a summary which is also a video that consists of only the activities that were present in the given video. We consider large changes as essential activities. Very minute changes are ignored. Video synopsis may also be applied for long movies consisting of many shots. In this case the method should be used for shot boundary detection and create video synopsis on each shot separately.
[1] D. Bordwell, K. Thompson: Film Art: An Introduction. 4th ed., McGraw-Hill, 1993.
[2] M. Christel, T. Kanade, M. Mauldin, R. Reddy, M. Sirbu, S. Stevens, and H. Wactlar. Informedia Digital Video Library. Communications of the ACM, 38(4):57-58 (1995).
[3] A. Dailianas, R. B. Allen, P. England: Comparison of Automatic Video Segmentation Algorithms. Proc. SPIE 2615, Photonics East 1995: Integration Issues in Large Commercial Media Delivery Systems, Andrew G. Tescher; V. Michael Bove, Eds., pp. 2-16
[4] S. Lawrence, C. L. Giles, A. C. Tsoi, A. D. Back: Face Recognition: A Convolutional Neural Network Approach. IEEE Trans. Neural Networks, Special Issue on Neural Network and Pattern Recognition, 1997, to appear
